ON-LINE STUDIUM

Český národní korpus
z hlediska učitele i žáka
| Korpus je
soubor počítačově uložených textů (v případě mluveného jazyka - přepisů
záznamu mluvy), který slouží k jazykovému výzkumu. K práci s tímto
korpusem slouží speciální
vyhledávací program. S jeho pomocí je možné vyhledávat slova a slovní
spojení v kontextu a zjistit jejich
frekvenci v korpuse
i původní textový zdroj.
Umožňuje i další zpracování nalezeného (např. abecední třídění apod.).
U některých korpusů lze vyhledávat i podle
slovních druhů. Podrobnější informace o korpusech naleznete zde.
Český národní korpus
(ČNK) je akademický projekt zaměřený na budování rozsáhlého počítačového
korpusu především psané češtiny. Pracuje na něm Ústav Českého národního
korpusu na Filozofické fakultě Univerzity Karlovy v Praze (ÚČNK). Od svého
založení roku 1994 má ÚČNK na starosti budování ČNK, jeho rozvoj a rovněž
činnosti související, zvláště v oblasti výuky a pěstování oboru
korpusová lingvistika.
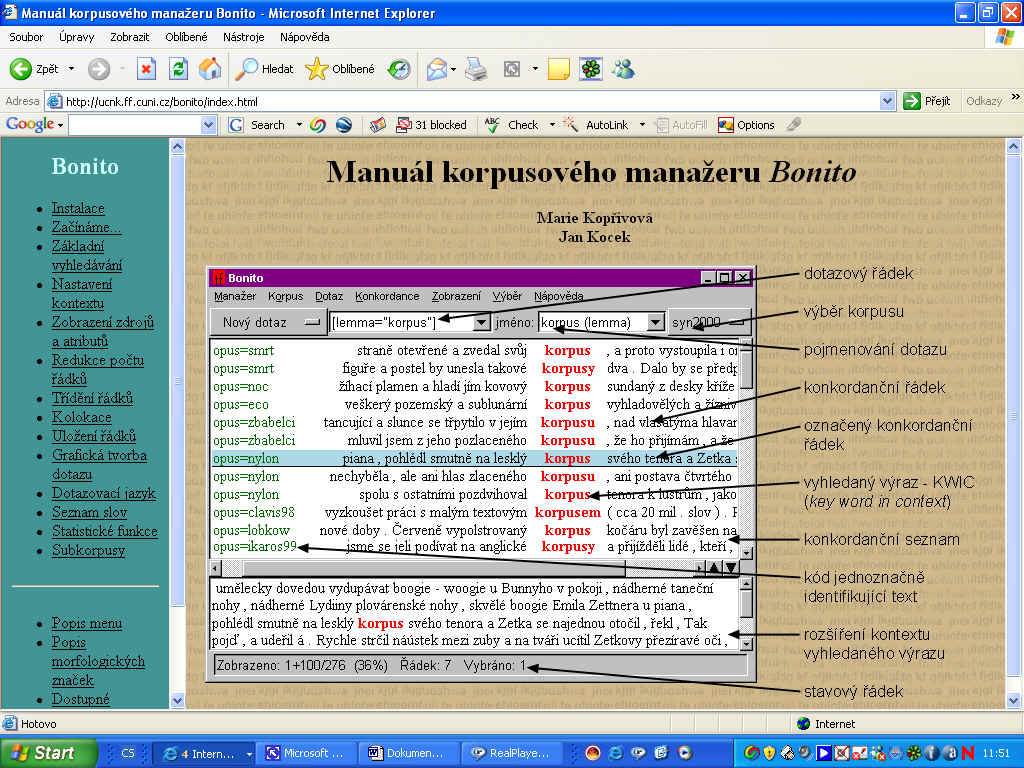
Vyhledávání tvaru slova nebo slovního spojeníHledaný tvar stačí zapsat do dotazového řádku a stisknout klávesu Enter.
stiskneme Enter a objeví se následující konkordance: (...)
(...) Stejně postupujeme, hledáme-li slovní spojení.
(...) (...) http://ucnk.ff.cuni.cz/index.html Odkazy: http://ucnk.ff.cuni.cz/index.html - Český národní korpus
Zpět na hlavní stránku.
|
|